In computer science, a data structure is a particular way of organizing data in a computer so that it can be used efficiently in computing platforms to meet organizational requirements. Different kinds of data structures are suited to different kinds of computing objectives, and some are highly specialized to specific specialized tasks. In this article, we provide a brief overview of the different kinds of Data Structure which may be found useful in Information Systems Development. What are Arrays? Imagine that we have 100 scores or 100 names of students. We need to read them through a computer program, process them and print them. We must also keep these 100 scores or names in memory, at least during the duration of the program. We might always instantiate a hundred variables, each with a different name. But instantiating 100 different names creates other problems. We need 100 references to read them, 100 references to write them and 100 references to process them in the memory block.

An array is a sequenced collection of elements, normally of the same data type, although some programming languages (especially some 4th Generation Languages) accept arrays in which elements are of different data types. We can refer to the elements in the array as the first element, the second element and so forth, until we get to the last element.  We can use loops to read write and operate upon the elements in an array. We can also use loops to process elements sequentially. The number of cycles (fetch, decode, and execute phases during the runtime of a program) the computer needs to perform is not reduced if we use an array. The number of cycles is actually increased, because we have the additional overhead cost (memory wise) of initializing, incrementing and testing the value of the member of the array. But our concern is not dependent only on the number of iterations within the code that forces us to think differently: it is the number of lines of code we may need to write within the program which throws greater chances of writing the code wrongly. What if we had to store thousands of elements, maybe millions? Scalability concerns forces us to look forward.
We can use loops to read write and operate upon the elements in an array. We can also use loops to process elements sequentially. The number of cycles (fetch, decode, and execute phases during the runtime of a program) the computer needs to perform is not reduced if we use an array. The number of cycles is actually increased, because we have the additional overhead cost (memory wise) of initializing, incrementing and testing the value of the member of the array. But our concern is not dependent only on the number of iterations within the code that forces us to think differently: it is the number of lines of code we may need to write within the program which throws greater chances of writing the code wrongly. What if we had to store thousands of elements, maybe millions? Scalability concerns forces us to look forward.

What are Multi-dimensional arrays? The arrays discussed so far are known as one-dimensional arrays because the data is organized linearly in only one direction. Many applications require that data be stored in more than one dimension. The indexes in a one-dimensional array directly define the relative positions of the element in actual memory. Figure below shows a two-dimensional array and how it could be stored in memory using row-major or column-major storage approach. Row-major storage is more common in most day to day application. 
Although we can apply conventional operations defined for each element of an array, there are some operations that we can define on an array as a data structure. The common operations on arrays as structures are searching, insertion, deletion, retrieval and traversal. Although searching, retrieval and traversal of an array is an easy job, insertion and deletion is time consuming. The elements need to be shifted down before insertion and shifted up after deletion. If we have a detailed list of a type of elements in which a lot of insertions and deletions are expected after the original list has been created, we should not use an array. An array is more suitable when the number of deletions and insertions is small, but a lot of searching and retrieval activities are expected.
What are Records? A record is a collection of related elements, possibly of different types, having a single name. Each element in a record is called a field. A field is the smallest element of named data that has meaning. A field has a type and exists in memory. Fields can be assigned values, which in turn can be accessed for selection or manipulation. A field differs from a variable primarily in that it is part of a record.

We can conceptually compare an array with a record and distinguish it too. This helps us to understand when we should use an array and when to use a record. An array defines a combination of elements, while a record defines the identifiable parts of an element. For example, an array can define a class of students (40 students), but a record defines different attributes of a student, such as id, name or grade. Array can consist of a single data type only while records may have multiple and different data-types. Just like in an array, we have two types of identifier in a record: the name of the record and the name of each individual field inside the record. The name of the record is the name of the whole structure, while the name of each field allows us to refer to that field. For example, in the student record, the name of the record is student, the name of the fields are student.id, student.name and student.grade. Most programming languages use a period (.) to separate the name of the structure (record) from the name of its components (fields).
What are Array of Records? If we need to define a combination of elements and at the same time some attributes of each element, we can use an array of records. For example, in a class of 30 students, we can have an array of 30 records, each record representing a student. Both an array and an array of records represent a list of items. An array can be thought of as a special case of an array of records in which each element is a record with only a single field. 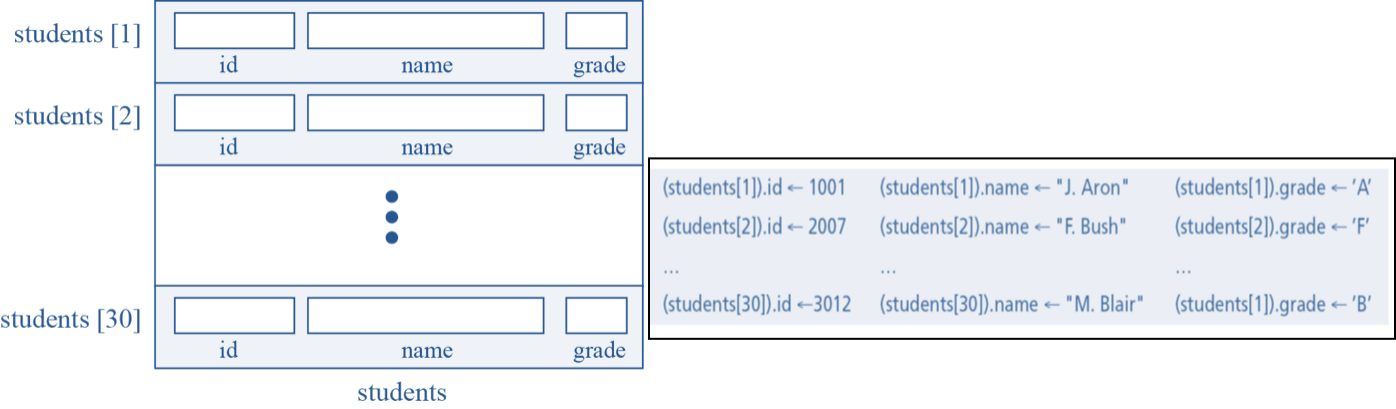 What are Linked Lists A linked list is a collection of data in which each element contains the location of the next element—that is, each element contains two parts: data and link. A linked list is a very efficient data structure for sorted list that will go through many insertions and deletions. A linked list is a dynamic data structure in which the list can start with no nodes and then grow as new nodes are needed. We define an empty linked list to be only a null pointer. A node can be easily deleted without moving other nodes, as needed with an array. The name of the list is the same as the name of this pointer variable.
What are Linked Lists A linked list is a collection of data in which each element contains the location of the next element—that is, each element contains two parts: data and link. A linked list is a very efficient data structure for sorted list that will go through many insertions and deletions. A linked list is a dynamic data structure in which the list can start with no nodes and then grow as new nodes are needed. We define an empty linked list to be only a null pointer. A node can be easily deleted without moving other nodes, as needed with an array. The name of the list is the same as the name of this pointer variable.

We show the connection between two nodes using a line. One end of the line has an arrowhead, the other end has a solid circle.

Both an array and a linked list are representations of a list of items in memory. The only difference is the way in which the items are linked together.

Linked list operations are as follows:

- Insertion into a linked list:
- Inserting into an empty list.
- Insertion at the beginning of the list.
- Insertion at the end of the list.
- Insertion in the middle of the list.
- Deleting a node
- Deleting the first node of a linked list
- Deleting a node at the middle or end of a linked list
- Retrieving a node
- Randomly accessing a node for the purpose of inspecting it
- Accessing a node for copying the data contained in it
- Traversing a linked list
As for arrays and records, we need to distinguish between the name of the linked list and the names of the nodes, the elements of a linked list. A linked list must have a name. The name of a linked list is the name of the head pointer that points to the first node of the list. Nodes, on the other hand, do not have an explicit names in a linked list, just implicit ones. What are Trees? A tree is a finite set of one or more nodes such that: There is a specially designated node called the root. The remaining nodes are partitioned into n>=0 disjoint sets T1, …, Tn, where each of these sets is a tree. We call T1, …, Tn the subtrees of the root.

What are Binary Trees? A binary tree is defined as a finite set of nodes situated within the tree that is either empty or consists of a root and two disjoint binary trees called the right subtree and the left subtree. Any tree can be transformed into binary tree through a series of transformation by left child-right sibling representation. The left subtree and the right subtree are distinguished, and separated from each other.

What are Binary Search Trees? BST is a special type of tree to facilitate faster data search. Its elements follow a certain order. Key property of a binary search tree is that for the Value at node, smaller values in stored in the left subtree and larger values are stored in the right subtree.
Example: X > Y and X < Z.

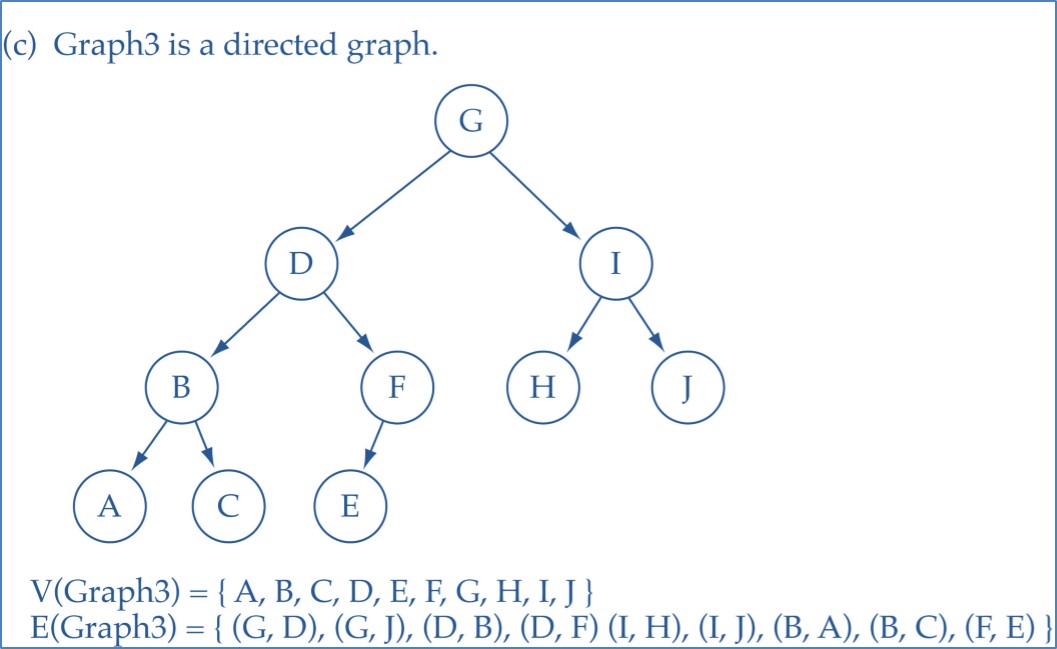
What are Graphs? A graph is basically a collection of nodes, each node having an element. A graph G is defined as follows: G=(V,E), where V(G): a finite, nonempty set of vertices and E(G): a set of edges (pairs of vertices). A data structure that consists of a set of nodes (vertices) and a set of edges that relate the nodes to each other. The set of edges describes relationships among the vertices.
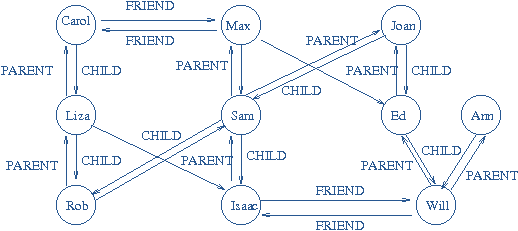
Graphs may be Undirected or Directed graphs. When the edges in a graph have no direction, the graph is called undirected. When the edges in a graph have a direction, the graph is called directed (or digraph)

Adjacent nodes are two nodes if they are connected by an edge. Path is a sequence of vertices that connect two nodes in a graph. Complete graph is a graph in which every vertex is directly connected to every other vertex. Weighted graph is a graph in which each edge carries a value.
Searching within a Graph Breadth-First-Searching (BFS): Look at all possible paths at the same depth before you go at a deeper level. Back up as far as possible when you reach a “dead end” (i.e., next vertex has been “marked” or there is no next vertex) Depth-First-Search (DFS): Travel as far as you can down a path. Back up as little as possible when you reach a “dead end” (i.e., next vertex has been “marked” or there is no next vertex)


You must be logged in to post a comment.